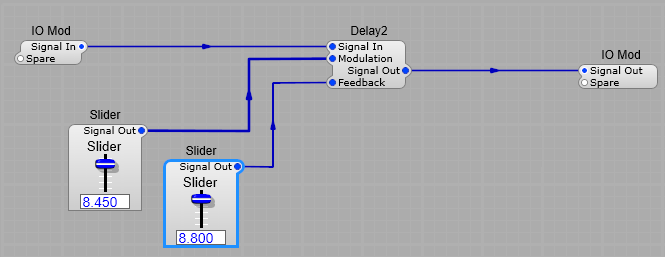
Consider the structure below, with the settings we have on the controls, there could potentially be a very long “tail” on the echo with such a feedback level. Ok so it reaches a low level, but it could take a very long time to reach what SynthEdit considers “silence”. Why does this matter? Well any modules further downstream are not getting shut down as they should be, and could still be active long after the human ear would fail to detect sound from the echo. This is a waste of CPU, as these modules are relying on SE telling them that they are not receiving audio, meaning they may not go into “sleep” mode for a long time. There is no risk of generating “Denormal” numbers as SE removes these internally.
Here is a quote from a regular contributor on the SE group Andrew Ainsley: “I sleep my modules when it is approximately under -110dBFS(noise floor of the best high-end AD converters, and humanly detectable dynamic range is approximately 120dB), and I’m assuming Delay2 sleeps at somewhere just before denormal mode, which is very very low, I tested up until -250dB and Delay2 is still active for quite some time afterwards…In practice say, with a max delay of 1 sec and 50% feedback, Delay2 will take in the order of minutes to go to sleep, which in practice is longer than a typical song, which seems rather pessimistic to me – i.e. in practice it will never sleep even though it can sleep, and thus it also keeps downstream modules awake while processing an inaudible signal. Switching it off sooner (in level) might cause audible clicks, but even if you assume the end-user will boost the level by an unrealistic value of say +120dB(!), you should still be safely able to switch off at about -230dBFS. “
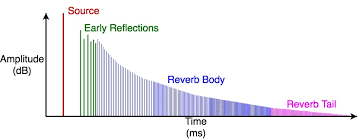
If we look at the chart below you can see what is meant by the tail, the red section is where the reverb/echo is tailing off (The purple section). At high feedback levels this tail can potentially become very long if there is no cut off point set other than 0, even though we can’t hear the sound. We want to keep the green and blue sections, but it would be very handy to be able to remove the inaudible section of the tail.
How can we stop this waste of CPU?
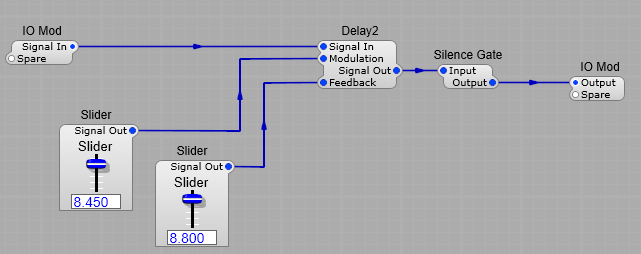
Fortunately Jeff has introduced a new module in SynthEdit to prevent this issue-the Silence Gate. This module does not wait for complete silence (0), but shuts off the audio at a level where we can’t actually perceive the sound. (Jeff has not quoted a level for this, just that it is completely inaudible.
SynthEdit is already highly efficient in terms of CPU usage, and has several features that automatically optimize the performance of your SynthEdit creations. However, it can’t compensate for any errors that may be made in construction, so with complex projects you may start to experience some performance issues. Common causes of high CPU usage: 1) Putting effects in the main Synthesizer container – this causes modules to use polyphony where it’s not needed, creating clones of modules which consumes CPU with no end result. 2) Hanging modules – they don’t sleep and hence they waste CPU 3) Oversampling – use with caution, this is very heavy on CPU usage. Make sure it’s really needed, used efficiently, and actually improves the output sound quality.
Keeping it under control. CPU usage is very dependent on the way a synth is put together. Often there are two ways to achieve the same result, with vastly different CPU usage. The more efficient your projects are, the better they will perform. DSP = more CPU cycles. Any module that generates or processes audio signals will use more CPU than a module that doesn’t. Audio requires that the processor is handling data at the current sampling rate set in preferences. In contrast sliders, knobs, and other controls or signals that don’t change often, like the MIDI to CV modules Pitch and Velocity outputs, can be considered control signals, which are handled in a different way, and at a much slower rate. Not quite DSP. An envelope generator module is somewhere in-between; during its Attack and Decay segments, it’s generating something close to audio rate data, and during the sustain section of the envelope, it’s generating a flat-line, control-rate signal.
1) Adding modules to the audio path is expensive in terms of CPU usage. 2) Adding modules to the control path is usually low cost in terms of CPU cycles.
Always keep effects outside of the main Synthesizer Container. A frequent beginners error is to put a reverb module inside the synthesizer’s container, which will then get applied to each individual note played, potentially eating a large number of CPU cycles. What is usually intended, is just one reverb, applied to the merged output (the reverb is added outside of the container.) Always add effects outside of your main synthesizer container to keep them from “Going Polyphonic”. See below for how it should be done: Main Synthesizer container, followed by another container for the effect modules.
Polyphony is not simple. Some modules force the signal into a monophonic format by default, for example; Delay2, Level Adjust and Pan. When every clone shares the same settings and these modules sit at the end of the signal chain they will be forced into the Monophonic mode.. However putting these monophonic effects between polyphonic modules imposes polyphony on them. Say you’re dealing with the following setup shown below:
Example: As it stands this won’t cause a problem, but then you decide to add a Filter after the Reverb JC module which is also Polyphonic after the monophonic effects, then forces all the modules in between the VCA and the Waveshaper, (Delay2 and Reverb JC) into polyphonic operation.
This is extremely wasteful of CPU resources, so either put the effects in their own container, followed by the filter, or put a voice combiner between the VCA and the Delay2 module as shown below. Even better would be to put the Delay2, Reverb JC, and the Moog Filter into their own container.
MIDI to CV2 use.
Please, please, please put the MIDI to CV2 module in the main synthesizer container, but do NOT put it in it’s own container, or outside of the main Synth container. When you do this it causes all sorts of strange effects such as pitch rising with each note played, and velocity not working correctly.
Avoid “Hanging” Modules:
A hanging module is on that is connected “downstream” from the MIDI-CV module but has no output wires. (See the example below)
SynthEdit identifies this as the ‘last’ module in the voice and monitors it’s output. However this module has no output wire which causes SynthEdit to never “sleep” the voice. This situation results in very high CPU consumption. This can often happen if a chain of modules is deleted for a modification and one gets missed – be careful to select all the modules in a chain if you are removing it, you may have had two filters and been switching between the two for testing or something similar. Also when you do have a situation where you’re switching between two filters don’t put the switch in the output like so:
You just created a hanging module. When you switch between filters, the de-selected one becomes a “hanging” module and never sleeps. The correct method is to switch input and output as shown below, with the switches controlled by the same List Entry module. The two extra control modules use far less memory and CPU than the hanging module in the previous method, as when you switch filters, the de-selected on is removed from the signal chain and goes into “sleep” mode conserving CPU.
De-Normal Numbers. De-Normal numbers should now no longer be an issue in Synthedit as there are FPU flags set to remove them. Taken from a post on synthedit@groups.io Q. “Jeff, are you perhaps setting some FPU flags to flush Denormals in SE ?” A. At least on Windows (I might include mac intel too I think…) controlfp_s( 0, _DN_FLUSH, _MCW_DN ); // flush-denormals-to-zero mode. This is why the Denormal diagnostics modules have been removed from the Synthedit modules. Thanks go to Elena Novaretti for pointing out this error to me.
De-normal numbers are very small floating point values that are inaudible, but are still processed by SynthEdit resulting in a waste of CPU resources (they will prevent all the downstream modules from sleeping). The symptom is sudden CPU spikes, especially during note tails. Note: CPU spikes during MIDI note-on events, or when moving controls are not an indication of a denormal number problem.
Detecting De-Normal numbers. If you suspect you may have a problem with de-normals, use the denormal Detector module on the output of the suspect module Connect the output to an LED Indicator module for visual indication. If denormal numbers are detected, you may use a denormal cleaner module to remove them.
Once you have positively identified the de-normals, then just remove the detector. The main cause of de-normals are modules with internal feedback, i.e. filters and delay modules. These types of modules usually have de-normal removal built-in, so if you suspect a denormal problem please report it to the module author, he/she may be able to release a fix.
Oversampling, what it is.
Oversampling should be used only when it’s really needed for an improvement in sound quality, as it pushes up the CPU usage quite dramatically. About Oversampling: In signal processing, oversampling is the process of sampling an audio signal at a sampling frequency significantly higher than the Nyquist rate. Theoretically, a bandwidth-limited signal can be perfectly reconstructed if sampled at the Nyquist rate or above it. The Nyquist rate is defined as twice the bandwidth of the signal. Oversampling is capable of improving resolution and signal-to-noise ratio, and can be helpful in avoiding aliasing and phase distortion by relaxing anti-aliasing filter performance requirements. A signal is said to be oversampled by a factor of N if it is sampled at N times the Nyquist rate. For example, we have a system with a Nyquist limit of 44kHz, but it’s actually sampled at 88kHz, then it would be oversampled by a factor of 2, so if the sample rate is taken up to 132kHz then we are oversampling by a factor of 3. Why oversample? There are four good reasons for performing oversampling: 1) To improve anti-aliasing performance (the higher the sample rate, the lower the level of the aliasing by products) 2) To increase resolution 3) To reduce noise and 4) It’s much easier to reduce aliasing distortion during sampling than after the sampling process (in fact reducing it after sampling is almost impossible). Oversampling and Anti Aliasing. Oversampling can improve anti-aliasing. By increasing the bandwidth of the sampling system, the job of the anti-aliasing filters is made simpler. Once the signal has been sampled, the signal can be digitally filtered and then down sampled to the required sampling frequency. In DSP technology, any filtering systems associated with the down-sampled audio are easier to put in place than an analogue filter system that would be required by a non-oversampled audio design. Oversampling and effects. Controversial subject, but an effect really isn’t going to get much of an improvement in sound quality (if any), but your CPU usage is going to increase substantially.